SparkJava: Getting Started
A more clear tutorial
Preliminaries: you need Java 1.8 and Maven
To get started with SparkJava, you should have, at a minimum, the following in your computing environment:
- Java 1.8 or higher (this is needed because SparkJava depends on Lambda functions which were introduced in Java 1.8)
- To check for Java 1.8, use
java -version
- To check for Java 1.8, use
- Maven
- To check for Maven, use
mvn -version
- To check for Maven, use
Here’s an example of sane output for a suitable computing environment (this happens to be from csil.cs.ucsb.edu during September 2016 :
-bash-4.3$ java -version
openjdk version "1.8.0_91"
OpenJDK Runtime Environment (build 1.8.0_91-b14)
OpenJDK 64-Bit Server VM (build 25.91-b14, mixed mode)
-bash-4.3$ mvn -version
Apache Maven 3.2.5 (NON-CANONICAL_2015-04-01T06:42:27_mockbuild; 2015-03-31T23:42:27-07:00)
Maven home: /usr/share/maven
Java version: 1.8.0_91, vendor: Oracle Corporation
Java home: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.91-2.b14.fc22.x86_64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.4.14-200.fc22.x86_64", arch: "amd64", family: "unix"
-bash-4.3$
Here’s output where Java works, but Maven doesn’t:
Phills-MacBook-Pro:~ pconrad$ java -version
java version "1.8.0_31"
Java(TM) SE Runtime Environment (build 1.8.0_31-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode)
Phills-MacBook-Pro:~ pconrad$ mvn -version
-bash: mvn: command not found
Phills-MacBook-Pro:~ pconrad$
Since Maven is pure Java software, installing is as simple as downloading the distribution, and then making sure the appropriate bin directory is in your path. We’ll defer the details of that process for now, and leave it as an exercise to the student to figure it out—or just use a platform where it is already installed (such as CSIL.)
The short version
- Clone the code in this github repo: https://github.com/pconrad-webapps/sparkjava-hello
- Read the README.md and do what it says to do.
- Enjoy a SparkJava HelloWorld.
If you just want to get something working quickly with SparkJava, this short version is the way to go. You won’t understand as much of the Maven Magic that’s making everything work, and if it breaks you won’t know how to fix it. But you’ll be up and running quickly.
If instead, you need to understand, then the long version takes you through building everything up from scratch.
The long version
This version indicates how the code in that other github repo came to be, a little bit at a time.
We start with Maven
Like it or not, you can’t really do SparkJava without using Maven, or one of the alternatives to Maven such as Gradle, Ivy, or SBT. Plain old Ant isn’t going to cut it. Sorry. So let’s just dig in.
Maven is a build manager similar to the make utility used with C/C++, or the ant utility commonly used with Java.
Instead of a makefile or a build.xml file, Maven uses a file called pom.xml which stands for Project Object Model.
But, Maven requires a bit of getting used to. You’ll probably want to read through this Maven in 5 minutes tutorial, and work through it at least once on a separate “Hello World” type of project that does NOT involve SparkJava, just to get used to it, before you try Maven on SparkJava.
Once that’s done, you can proceed with the steps below.
A minimal pom.xml for a SparkJava project
As explained here a minimal pom.xml file for a SparkJava hello world project might start out looking like this.
<project>
<!-- model version - always 4.0.0 for Maven 2.x POMs -->
<modelVersion>4.0.0</modelVersion>
<!-- project coordinates - values which uniquely identify this project -->
<groupId>com.mycompany.app</groupId>
<artifactId>my-app</artifactId>
<version>1.0</version>
<!-- library dependencies -->
<dependencies>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.5</version>
</dependency>
</dependencies>
</project>
A few things to note:
- The highest level xml element is
<project> - The
<groupId>element should probably be changed fromcom.mycompany.appto something that uniquely identifies your course, quarter, and either your UCSBNetID, githubid, or csil username, e.g.edu.ucsb.cs56.f16.lab03.jgaucho - The most important part that actually matters in terms of making the thing work properly is the place where
the
<dependency>element where it indcates that this project depends on an artifact calledspark-coreversion2.5fromcom.sparkjava. This part is the part that will cause the appropriate jar files, and any jar files those jar files depend on, to get downloaded, and put into the classpath.
But it is enough to have this pom.xml? Of course not. You also need at least one Java source file, e.g. this one:
import static spark.Spark.*;
public class HelloWorld {
public static void main(String[] args) {
get("/hello", (req, res) -> "Hello World");
}
}
And that means we have to worry about where to put that HelloWorld.java source file in a directory structure. Maven doesn’t want us to just have HelloWorld.java and pom.xml as siblings in a simple flat directory. It wants a specific directory structure. And the best way to get that directory structure is to just let Maven build it for us.
For the command:
mvn archetype:generate -DgroupId=com.mycompany.app -DartifactId=my-app -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
You get:
my-app
|-- pom.xml
`-- src
|-- main
| `-- java
| `-- com
| `-- mycompany
| `-- app
| `-- App.java
`-- test
`-- java
`-- com
`-- mycompany
`-- app
`-- AppTest.java
So, let’s try this with a command more appropriate to our local naming conventions. NOTE: substitute your own id
in place of jgaucho, e.g. jsmith, kchen, etc.
mvn archetype:generate -DgroupId=edu.ucsb.cs56.f16.helloSpark.jgaucho \
-DartifactId=HelloSparkJava \
-DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Here is the directory tree we get:
-bash-4.3$ tree
.
└── HelloSparkJava
├── pom.xml
└── src
├── main
│ └── java
│ └── edu
│ └── ucsb
│ └── cs56
│ └── f16
│ └── helloSpark
│ └── pconrad
│ └── App.java
└── test
└── java
└── edu
└── ucsb
└── cs56
└── f16
└── helloSpark
└── pconrad
└── AppTest.java
18 directories, 3 files
-bash-4.3$
The pom.xml that results is this one:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-inst
ance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>edu.ucsb.cs56.f16.helloSpark.pconrad</groupId>
<artifactId>HelloSparkJava</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>HelloSparkJava</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
To it, we add the important part, namely this, as a sibling of the other dependency already there, so that now the dependencies part looks like this:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.5</version>
</dependency>
</dependencies>
We also find that way, way down in this directory:
HelloSparkJava/src/main/java/edu/ucsb/cs56/f16/helloSpark/pconrad
There is an App.java file with these contents:
package edu.ucsb.cs56.f16.helloSpark.pconrad;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
System.out.println( "Hello World!" );
}
}
We are going to replace that with a main program that actually runs a SparkJava webapp. Note that other than the package name edu.ucsb.cs56.f16.helloSpark.pconrad, and the name
of the class (App instead of HelloWorld), this is identical to the example SparkJava webapp in the tutorial
package edu.ucsb.cs56.f16.helloSpark.pconrad;
import static spark.Spark.*;
public class App {
public static void main(String[] args) {
get("/hello", (req, res) -> "Hello World");
}
}
Now we are ready to do the maven magic. We type mvn package, which according to the Maven in 5 minutes guide, has the effect of doing all of the following “phases” of a Maven project:
- validate
- generate-sources
- process-sources
- generate-resources
- process-resources
- compile
But it doesn’t work, because it tries by default, to produce code that is backwards compatible with Java 1.5. And we get this error:
/cs/faculty/pconrad/sparkjava/HelloSparkJava/src/main/java/edu/ucsb/cs56/f16/helloSpark/pconrad/App.java:[7,34] lambda expressions are not supported in -source 1.5
[ERROR] (use -source 8 or higher to enable lambda expressions)
To fix this, we have to add the following bit of pom.xml magic sauce. This can go in between the <url>...</url> element and the <dependencies>...</dependencies> element:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
And it appears to work! But what did it do? Let’s try tree again and see if we can figure that out:
-bash-4.3$ tree
.
├── pom.xml
├── src
│ ├── main
│ │ └── java
│ │ └── edu
│ │ └── ucsb
│ │ └── cs56
│ │ └── f16
│ │ └── helloSpark
│ │ └── pconrad
│ │ └── App.java
│ └── test
│ └── java
│ └── edu
│ └── ucsb
│ └── cs56
│ └── f16
│ └── helloSpark
│ └── pconrad
│ └── AppTest.java
└── target
├── classes
│ └── edu
│ └── ucsb
│ └── cs56
│ └── f16
│ └── helloSpark
│ └── pconrad
│ └── App.class
├── generated-sources
│ └── annotations
├── generated-test-sources
│ └── test-annotations
├── HelloSparkJava-1.0-SNAPSHOT.jar
├── maven-archiver
│ └── pom.properties
├── maven-status
│ └── maven-compiler-plugin
│ ├── compile
│ │ └── default-compile
│ │ ├── createdFiles.lst
│ │ └── inputFiles.lst
│ └── testCompile
│ └── default-testCompile
│ ├── createdFiles.lst
│ └── inputFiles.lst
├── surefire-reports
│ ├── edu.ucsb.cs56.f16.helloSpark.pconrad.AppTest.txt
│ └── TEST-edu.ucsb.cs56.f16.helloSpark.pconrad.AppTest.xml
└── test-classes
└── edu
└── ucsb
└── cs56
└── f16
└── helloSpark
└── pconrad
└── AppTest.class
44 directories, 13 files
-bash-4.3$
In that big mess, you’ll see that the classes for App.java and AppTest.java got put into a couple of classes and test-classes directories. Even more, there is a .jar file for our project that we can run.
So we might try running that with this command, but we run into a problem:
-bash-4.3$ java -jar target/HelloSparkJava-1.0-SNAPSHOT.jar
no main manifest attribute, in target/HelloSparkJava-1.0-SNAPSHOT.jar
-bash-4.3$
The jar has no main class. Sad. So, what do we do?
Later on, we’ll come back and fix the problem of no main mainfest attribute, because honestly, there should be one. But for now, we know that the main class we want is:
edu.ucsb.cs56.f16.helloSpark.pconrad.App
Of course. You knew that right?
So, we can use this command:
java -cp target/HelloSparkJava-1.0-SNAPSHOT.jar edu.ucsb.cs56.f16.helloSpark.pconrad.App
But that gives us a different error. It turns out that Maven didn’t package up all the jars on which the project depends along with the classes in our project. So we get an error that the class spark/Request is not known:
Exception in thread "main" java.lang.BootstrapMethodError: java.lang.NoClassDefFoundError: spark/Request
at edu.ucsb.cs56.f16.helloSpark.pconrad.App.main(App.java:7)
There is a recipe to tell Maven to fix both problems at once: i.e. to create a so-called uber jar (that’s really what they call it) that has all the dependencies baked in, and to specify which main to run so that the jar is executable, all in one fell swoop.
Regrettably, it looks heinous. It takes the form of another “plugin” that we put into our pom.xml, right next to the other plug in. Here’s what it looks like. Note the `
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>edu.ucsb.cs56.f16.helloSpark.pconrad.App</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
But, with that in place, now all is well. Here’s what that looks like:
-bash-4.3$ java -jar target/HelloSparkJava-1.0-SNAPSHOT.jar
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
...
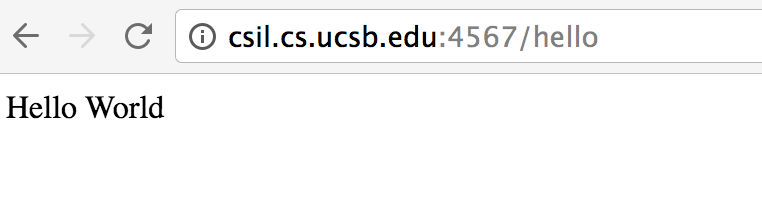
At this point, on whatever machine we are running on (e.g. csil.cs.ucsb.edu) if we go to port 4567, /hello, we’ll see this web server running, e.g.:
Getting it running on Heroku
To get this to run on Heroku, we only need to do these things:
- Add a one line text file called
Procfilethat has this line in it:web: java -jar target/HelloSparkJava-1.0-SNAPSHOT.jar -
Add code to set the port number from an environment variable, like this:
- A minimalist one-liner approach. This may crash if PORT is not defined.
Spark.port(Integer.valueOf(System.getenv("PORT"))); // needed for Heroku - A more robust approach:
try { Spark.port(Integer.valueOf(System.getenv("PORT"))); // needed for Heroku } catch (Exception e) { System.err.println("NOTICE: using default port. Define PORT env variable to override"); }
- A minimalist one-liner approach. This may crash if PORT is not defined.
- Using the heroku toolbelt, type
heroku create, and thengit push heroku master.
This should run the pom.xml file to create the uberjar, then execute the Procfile to start the webapp running on the port specified by Heroku.
More on SparkJava: Getting Started
- SparkJava: Authentication—login/logout, and securing various pages in your app
- SparkJava: Bootstrap—Adding a nicer looking UI, with common navigation, drop down menus, etc.
- SparkJava: Facebook API—Authenticate with Facebook, then access the Facebook API
- SparkJava: Getting Started—A more clear tutorial
- SparkJava: Github API—Authenticate with Github, then access the Github API
- SparkJava: Image Files—and any other static files your application needs
- SparkJava: MongoDB—Using the NoSQL database MongoDB with SparkJava
- SparkJava: pac4j—Securing a SparkJava webapp, with options for OAuth or LDAP
- SparkJava: RESTful APIs—Creating RESTful APIs with SparkJava
- SparkJava: SLF4J—What is the Simple Logging Framework For Java, and how to configure it
- SparkJava: Templates—The various template engines you can use with SparkJava